Ultimate Openai Playground Settings Guide



The openai playground has become one of the most popular ai tools. This guide will go through the openai playground settings to help guide you in building better prompts.
If this is your first time working with the openai playground, checkout our in depth guide here of how the openai playground works.
Building gpt-3 prompts can be difficult at first, but after reading this guide you should have a better understanding of the following openai playground settings:
- Choosing the best model
- Prompt temperature settings
- Max Length
- What are stop sequences
- Top P
- Frequency penalty
- Presence penalty
- Best of setting
- Inject start text and inject restart text
Which openai model should you use?
GPT-3 are programmed ai models that help understand and generate natural language. There are 4 different types of models such as Davinci, Curie, Babbage, and Ada. Depending on the model of choice a couple of factors will come into place.
Davinci model
This model is the most expensive but also the most powerful. This model does not require as much instructions as other models. When practicing in the openai playground, its best to use the davinci model during testing.
Curie model
Curie works well when working with ai generation that requires classification or summarization. Although davinci is stronger, curie is very good at performing chatbot related functions. If looking to develop some form of a Question and answer chatbot, the curie gpt-3 model will work great.
Babbage model
The babbage model works great for task that are pretty straight forward such as classification task.
Ada model
An lastly the ada model is usually the fastest and performs great at task such as parsing text, simple classification, keywords and many other small ai related task. This model is also the cheapest which can make it more desirable to use in production.
To get a better understanding of gpt-3 cost structure read our more in depth article here.
Openai playground temperature settings
Temperature helps control how random your generated response will be. This will be one of the most adjusted openai playground settings. GPT-3 was built to help generate an ai generated response depending on your prompts.
Temperature is measured on a scale from 0 to 1.0. The closer you are to 0, the more repetitive your and concise your responses may be. This may be desired when you dont want the openai api to ramble off topic too much.
As you start to move temperature closer to 1, the output may start to get more of a curated response. There is no best temperature settings since it will depend on your prompts use case.
When adjusting the temperature setting, its best to keep only move up in small increments and keep track of where its best responses are.
Determining openai max length for completions
To better control the length of completions, the max length setting helps keep the response length reasonable. Completion length is measured in tokens vs actual characters.
When working inside the openai playground, The max length not only controls how much of a response that can be generated but also can help you put a control on cost.
The max length is shared between whats in the playground box and the generated response. The davinci gpt-3 model can process up to 4000 tokens and the other models up to 2027 tokens.
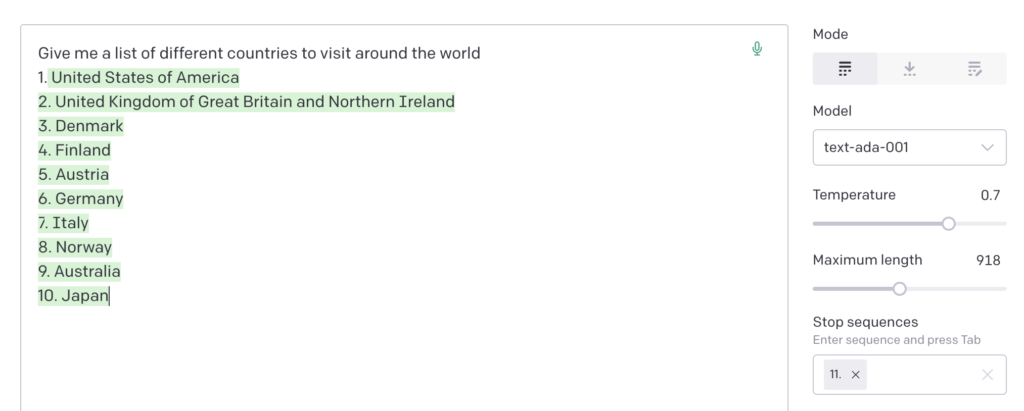
What is a stop sequence in the openai playground settings
Stop sequences helps the ai know when to stop at a desired point. Most times a return character or the Enter key is sufficient. For example lets say you have a list that is outputted in your prompt and you only need 10 items.
You can use the number 11 as your stop character to make sure it stops at 10. Your stop sequence can essentially be anything.
What does Top P mean?
Top P helps control how the model controls the randomness of the results. Top P ranges in value from 0 to 1. This openai playground setting works in comparison to the temperature setting.
In my testing I have not found it much usefully to mess with this setting, but better to stick with adjusting the temperature setting.
Frequency and Presence Penalty
If you start to notice your prompts are repeating the same outputs verbatim, adjusting this setting will help in decreasing that from happening.
Frequency and presence penalty can be adjusted from 0 to 2. I have always found no reason in my testing to have to change this. Sometimes you can get away with adjusting your prompts to better word the outputs.
Openai Best Of Setting
Adjust and use this setting with caution. Changing this to anything more than 1 could potentially eat through your token cost a lot faster. Best of takes multiple completions of the output and chooses the best one to output.
This all happens server side. If not using a setting of 1, The streaming of the output will not be displayed. The more you add, the speed of the completion could be decreased as well.
Inject Start and Restart Text
When working with prompts that require a strict starting and ending, these settings can be really important. For example Lets say you’re building a question and answer bot.
The start text could be you needing to enter anything in at the beginning of your prompt. I like to personally use the start and restart text when building prompts that require questions and answers.
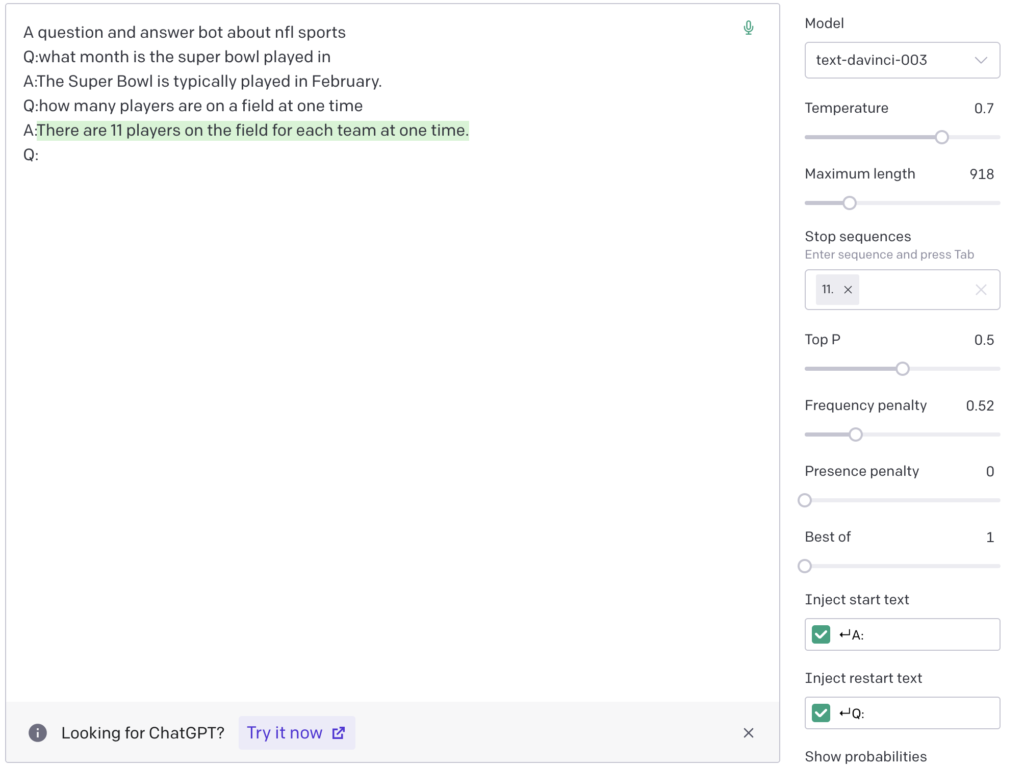
I have the carriage return and the letter A: and Q being used. In the prompt field you can see the Q: being injected back into the prompt after the answer is displayed.
Conclusion
This guide should give you a better understanding of the openai playground settings. Getting the correct settings can really be a big difference in building the best prompts for your application.





